Devpost
Participate in our public hackathons
Devpost for Teams
Access your company's private hackathons
Grow your developer ecosystem and promote your platform
Drive innovation, collaboration, and retention within your organization
By use case
Blog
Insights into hackathon planning and participation
Customer stories
Inspiration from peers and other industry leaders
Planning guides
Best practices for planning online and in-person hackathons
Webinars & events
Upcoming events and on-demand recordings
Help desk
Common questions and support documentation
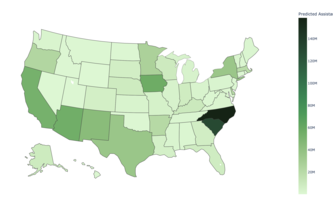
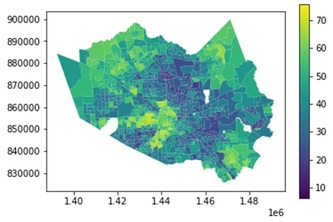
Utilized linear regression model and choropleth maps to determine which states are most in need for mammography facilities.
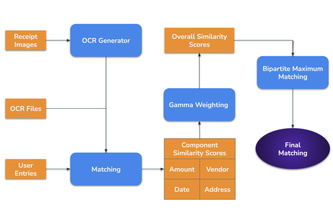
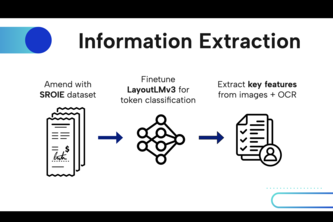
Intelligent record matching for receipts.
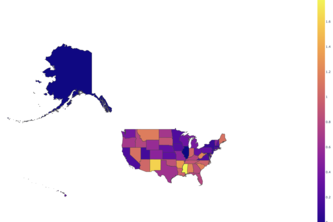
Predicting ideal collaborators given empirical renewable energy investment data using ensemble method with random forest and ARIMA
With the explosion of renewable energy companies, we aim to build a model to shape Chevron’s renewables investment strategy.
How can we predict renewable energy investments for all given states? After filtering out MSN's that were duplicates and training a regression model, we obtained good results from a simple model.
Monitoring money mobilizing medical mammograms.
Predicting state populations with least squares regression & determining the relative risk of new breast cancer cases per state by incorporating external data on cancer rates in different age groups.
“Let’s get it off our chests!” - MaMaFund is a data science project designed to fill the gaps in current mammography coverage and offer insights for better resource allocation
Used Lloyd's Algorithm to cluster states after assigning states scores to determine priority of federal fund allocation.
Using various prediction algorithms, we were able to accurately predict 7 of the top 10 states by amount of assistance in funding renewable resources so Chevron can efficiently invest in clean energy.
Unlocking the key to voter turnout - this datathon project analyzes Baker Ripley's Get Out the Vote efforts to pinpoint effective strategies for boosting voter participation in future elections.
We are creating machine learning models to solve the Chevron Challenge.
We used a donut model to extract receipt features. We matched the highest fuzzy ratio between test data rows and after receipt features were concatenated as one string with over 80% accuracy.
Matching images of receipts to purchase logs – made easy.
Given a set of receipts, some with OCR data, and a set of "users" tagged with total price, vendor name, date, and address, we can accurately match receipts and users together even with many typos!
This is a project targeting the Chevron track. We are using neural network machine learning from tensorflow to predict the total amount of assistance for a given state.
We're the data wranglers and we predicted the renewable energy investment of states using a composite state-by-state model.
We did analyses of the cost efficacy and efficiency of BakerRipley's GOTV outreach initiative for the November 2022 Texas General Election in Harris County.
BillNet: An Improved Transfer Learning Based Approach for Receipt Matching
We look at user logs, images and associated OCR data to match pictures of receipts with the user logs.
Bill.com Matching Challenge with Named Entity Recognition
We combine the data provided by Chevron with by-industry economic (employment and GDP) data, population data, and state political data. We train a NN to predict renewable energy investments.
Bill.com Challenge - NN for date/time receipt prediction
Doing the lord's work with your receipts using OCR, Regular expressions, and Natural Language processing.
1 – 24 of 47